Our mission
The predictions of machine learning (ML) systems often appear fragile, with no hint as to the reasoning behind them—and may be dangerously wrong. This is unacceptable: society must be able to trust and hold to account ML. Our mission is to advance the security and privacy of machine learning. We empower ML developers and engineers to develop and design ML systems that are secure. This often leads us to explore the broader question of what makes a machine learning system trustworthy.
Our team
Our lab is led by Prof. Nicolas Papernot and is located at the University of Toronto and the Vector Institute, both located in downtown Toronto (Canada). Get to know our team by browsing our list of current and past members, and if you are interested in joining please read the following page.
Our work
A selection of our work towards advancing trustworthy machine learning includes:
Machine Unlearning - SISA
If our data is used to train a Machine Learning model, we always have the right to revoke the access and requesting the model to unlearn our data. In this work, we propose a framework named SISA training that expedites the unlearning process by strategically limiting the influence of a data point in the training procedure. The high-level idea is to (a) aggregate models trained on different partitions of the dataset (so one unlearning request does not influence the whole model) and (b) train the models on incremental sets of data and save checkpoints while training (so we could load the one right before the model saw the unlearned data to save retraining time). For more details, please check our blog post or the paper.
Proof of Learning
As part of Proof of Learning (PoL), we study how to verify if someone actually trained a model. For instance, given a publicly hosted ML model, can a trusted arbitrator determine whether it is stolen or not? At high level, a PoL is a sequence of states containing information necessary to reproduce each training update, including intermediate model checkpoints, data points, and hyperparameters, etc. In the paper, we validated that such a proof can be used by the arbitrators to resolve ownership conflicts and to have a permanent record of the entire training effort. Since PoL is essentially a form of logging, there is no change to the training procedures and no impact on the model utility. For more details, please check our blog post or the paper..
Entangled Watermarks
Being similar to watermarks of images, the goal of watermarking Deep Neural Networks (DNNs) is to allow the owners to claim ownership of this valuable intellectual property. This is usually done by leveraging unused model capacity to have the DNN overfit to special outlier data (a.k.a. watermarked data). Entangled Watermarking Embeddings (EWE) encourages the DNNs to learn common features for data from the task distribution and watermarked data. Thus, it is robust against knowledge transfer, and removing it would result in performance drop of the classification task. For more details, please check the paper.
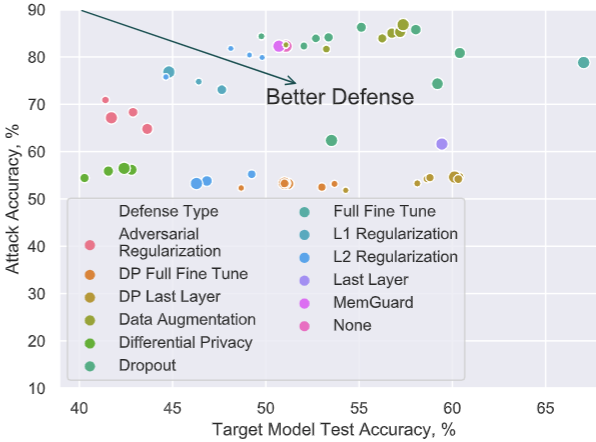
Label-Only Membership Inference
We show that the most restricted adversary -- operating in a label-only regime -- can perform on-par with traditional confidence-vector adversaries. Because of this, many defenses that perform `confidence-masking' can be bypassed, rendering them not viable. In a rigorous evaluation, we show that only differential privacy and strong L2 regularization can defend against membership inference.
To learn more about the rest of our work, you can find out more on:
- our publications by browsing our papers
- code artifacts released by our lab on our GitHub page
- posts published on our blog
Our sponsors
We would like to acknowledge our sponsors, who support our research with financial and in-kind contributions. Current and past sponsors include Canada Foundation for Innovation, CIFAR, DARPA, Intel, Meta, Microsoft, NFRF, NSERC, Ontario Research Fund, University of Toronto, the Vector Institute.