How to steal modern NLP systems with gibberish?
by Kalpesh Krishna and Nicolas Papernot
Overview
Fine-tuning models has emerged as one of the popular approaches to natural language processing (NLP). Rather than train models from random initialization, that is from scratch, models are repurposed: previous model parameters are loaded as initializations and training continues on data from a new distribution. The success of BERT is indicative of this trend. In this blog, we ask “what are the security implications for NLP models trained in this way?” In particular, we take a look at model extraction attacks where the adversary queries a model with the hope of stealing it.
Typically, queries made by the adversary to steal a model need to be constructed from data that is sampled from the same distribution than the victim model was trained on. However, we present in this blog post results from our paper “Thieves on Sesame Street! Model Extraction of BERT-based APIs”, which will be presented at ICLR 2020. In this paper, we showed that it’s possible to steal BERT-based natural language processing models without access to any real input training data. Our adversary feeds nonsensical randomly-sampled sequences of words to a victim model and then fine-tunes their own BERT on the labels predicted by the victim model.
The effectiveness of our method exposes the risk of publicly-hosted NLP inference APIs being stolen if they were trained by fine-tuning. Malicious users could spam APIs with random queries and then use the outputs to reconstruct a copy of the model, thus mounting a model extraction attack.
What are model extraction attacks?
Let’s say a company hosts a publicly accessible machine learning inference API. We will refer to this as the victim model in the rest of this post. This API allows users to query a machine learning model with any input of their choice and it responds with the model’s prediction. This is for instance the case with translation tools offered by Amazon and Google on their respective cloud platforms: users can submit sentences in one language and the API returns the same sentence in a different language. The translation is performed by a translation model, often a neural network.
A model extraction attack happens when a malicious user tries to “reverse-engineer” this black-box victim model by attempting to create a local copy of it. That is, a model that replicates the performance of the victim model as closely as possible. If reconstruction is successful, the attacker has effectively stolen intellectual property. It does not have to pay the provider of the original API anymore to have the model predict on new data points. Moreover, this stolen copy could be used as a reconnaissance step to inform later attacks. For instance, the adversary could use the stolen model to extract private information contained in the training data of the original model, or to construct adversarial examples that will force the victim model to make incorrect predictions.






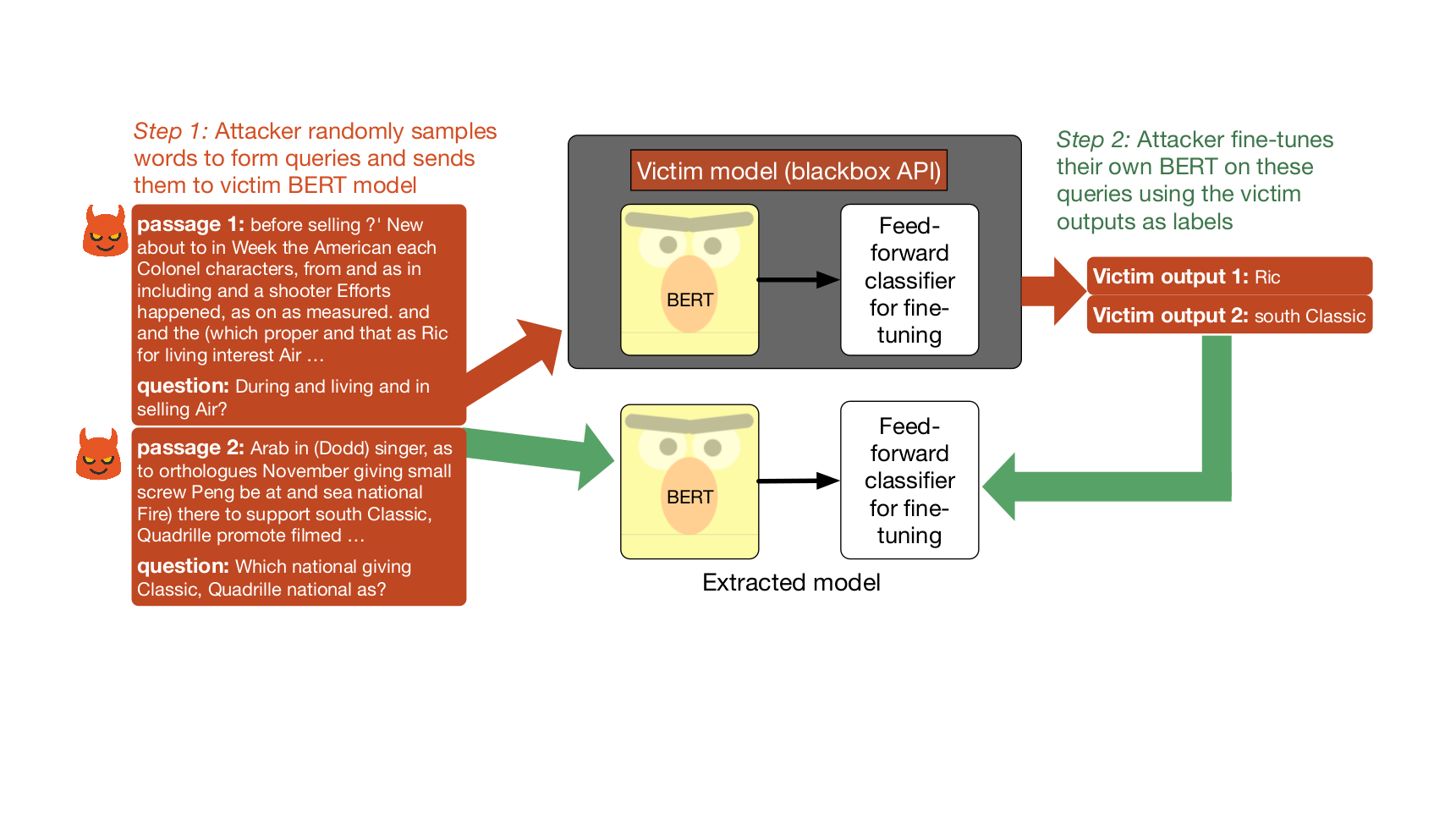
As shown in this animated slide deck, the most popular approach to carry out this attack is via a process resembling distillation. Attackers send a large number of queries to the API. These queries are unlabeled inputs, which the adversary is looking to have labeled. The API will do exactly just that by returning the victim model’s prediction to the adversary. In our work, we show that the adversary only needs to have access to the model’s label. This means that the adversary does not always need to have access to the confidence value — often returned by the model along with its prediction — for the model extraction attack to be successful. The adversary then collects the predicted outputs returned by the API. These query-output pairs are used by the attacker as training data to reconstruct a copy of the victim model. From now on, we will call this local copy of the victim model the extracted model.
How is model extraction different from distillation?
There are three important differences between model extraction and distillation.
- Training Data - Distillation usually assumes access to the original training dataset or a different dataset sampled from the same distribution than the original training data’s distribution. In model extraction settings, the training data is often unknown to the attacker.
- Access to Victim Model - In model extraction, attackers have a limited access to the victim model: most of the time, they can in fact only get access to the label predicted by the model. Instead, distillation is performed with access to the model’s confidence scores for each possible output. Prior work has also shown that distillation can be improved by using intermediate hidden representations of the teacher. This requires white box access to the victim model, which is not a realistic assumption to make when stealing a model.
- Goal - Distillation aims to transfer knowledge from a big model to a small model. That is, distillation is used to decrease the number of parameters needed to store the model. This is often used as a way to support training large models on datacenters with lots of computing resources and then later deploy these models on edge devices with limited computing resources. This compression is not needed in model extraction. Instead, the adversary is primarily interested with the accuracy of the extracted model with respect to the victim model.
How much do these attacks cost?
Commercially available inference APIs are cheap - Based on costs advertised publicly on Google Cloud API’s website, we estimated that it would cost just:
- $62.35 to extract sentiment labels on 67,000 sentences. This corresponds to the size of SST2, a popular dataset for NLP;
- $430.56 to extract a speech recognition dataset of 300 hours of telephone transcripts. This is roughly the size of Switchboard, a popular speech recognition dataset;
- $2,000 to extract 1 million translation queries (each with 100 characters).
Several APIs allow a limited number of free queries per IP address, making it possible to collect datasets for even cheaper if data collection is distributed across multiple IP addresses. This is called a Sybil attack in the security literature.
What kind of models do we study in our paper?
We study model extraction in modern NLP settings which heavily rely on BERT. A key focus of our work is using nonsensical sequences of words as queries. Modern natural language processing systems are typically based on BERT, a large transformer trained using a self-supervised objective on Wikipedia. BERT produces rich natural language representations which transfer well to most downstream NLP tasks (like question answering or sentiment analysis). Modern NLP systems typically add a few task-specific layers on top of the publicly available BERT checkpoint and fine-tune the whole model with a small learning rate.
In our paper, we perform model extraction in this transfer learning setting, where the victim model is assumed to be a BERT-based classifier. In this blog post, we present a subset of the results included in our paper. We look at three NLP datasets which are among the most popular benchmarks used to evaluate pre-trained language models like BERT.
The first two datasets (SST2 and MNLI) form a part of the GLUE benchmark to evaluate pretrained language models. The third dataset is SQuAD, one of the most popular question answering datasets.
- SST2 - This is a binary sentiment classification task where the input is a sentence and the output is either positive or negative sentiment. It is the most common dataset for sentiment classification.
- MNLI - This is a three-way entailment classification task. The input is two sentences (a premise and hypothesis) and the output is either entailment (premise implies hypothesis), contradiction (premise contradicts hypothesis) or neutral (premise is unrelated to hypothesis). It is the most commonly used dataset for natural language inference.
- SQuAD - This is a reading comprehension dataset. The input is a paragraph and a question about the paragraph, and the output is a span of text from the paragraph which best answers the question. Note that unlike SST2 and MNLI, the output space is high dimensional. It is the most commonly used dataset in reading comprehension and question answering research.
What kind of queries does the attacker make in our paper?
We assume that the attacker has access to large pretrained language models, which are freely available. However, the attacker does not have access to the task-specific original training data used to create the victim model. Hence, we use two strategies to construct attack queries:
- The first strategy (
RANDOM) uses nonsensical, random sequences of tokens sampled from Wikitext103’s unigram distribution. - The second strategy (
WIKI) uses sentences / paragraphs from WikiText103. For tasks expecting a pair of inputs (MNLI, SQuAD), we use simple heuristics to construct the hypothesis (replace 3 words in premise with random words from Wikitext103) and question (sample words from the paragraph, prepend an interrogative word like “What” or “Where”, append a question mark at the end) respectively.
To get an idea of the kind of training data we used, look at the table below.

How well do these attacks perform?
Our model extraction attacks perform surprisingly well; extracted models are nearly as good as the victim model. Perhaps the most surprising result is that our model extraction attacks are effective despite the fact that they use sentences that do not have a meaning: our RANDOM strategy is already effective and the WIKI strategy performs even better.
This is very different from the image domain, where prior work found that random inputs made for a very query-inefficient heuristic to extract image classifiers. This may suggest an analog result for the extraction of image classifiers. The attacker might be able to perform better if they query the victim image classifier with images generated by randomly assembling small patches of pixels from natural images rather than sampling each pixel value randomly. These patches would not necessarily have to come from the victim model’s training set, they could be from any image dataset.
Concretely, the victim BERT-large SQuAD model reaches a dev set performance of 90.6 F1. With our RANDOM strategy, the model reaches 85.8 F1 score on the test set without seeing a single grammatically valid paragraph or question during training. With our WIKI strategy, performance jumps to 89.4 F1 without seeing a single real training data point.
| Number of Queries | SST2 (%) | MNLI (%) | SQuAD (F1) | |
|---|---|---|---|---|
| API / Victim Model | 1x | 93.1 | 85.8 | 90.6 |
RANDOM |
1x | 90.1 | 76.3 | 79.1 |
RANDOM |
upto 10x | 90.5 | 78.5 | 85.8 |
WIKI |
1x | 91.4 | 77.8 | 86.1 |
WIKI |
upto 10x | 91.7 | 79.3 | 89.4 |
We run experiments in two settings — controlled number of queries and uncontrolled number of queries. In the controlled setting, the number of queries used to attack the model is identical to the size of the dataset used to train the model. This is marked as “1x” in the table above. In the uncontrolled setting, we use up to 10 times the original dataset’s size to attack the victim model. Depending on the adversary’s query budget, one of these two settings is closer to a practical attack. However, understanding how well the attack works in uncontrolled settings is important for defenders to know how vulnerable their systems are.
Did language model pre-training make model extraction easier?
Attackers who fine-tune pretrained language models do better at extraction. We consider an alternative attack strategy where instead of fine-tuning BERT, attackers train QANet from scratch. That is, the attacker initializes the parameters of the extracted model with random values before training it. This strategy only achieves 43.2 F1 and 54 F1 using our RANDOM and WIKI heuristics for querying the victim model. This is a significant drop in performance compared to the fine-tuning attack results presented above. The same holds when our strategy is compared to another baseline: training the extracted model from scratch through distillation over the original training data only achieves 70.3 F1. We also show that pretrained language models offering superior performance to BERT, like XLNet, are more successful at model extraction compared to BERT.
Are some kinds of queries better for model extraction than others?
Next, we set out to understand whether there were queries that were better than others when it comes to extracting a model. The adversary would want to issue these queries first, especially if they can only make a limited number of queries.
Queries more likely to be classified with confidence by the victim model work best for model extraction. We considered the following strategy. We only kept RANDOM or WIKI queries when they were classified consistently by an ensemble of models. Specifically, we trained multiple copies of the victim model. This was done by training the same architecture from different random seeds. When all victim models predict the same output on a query, we say that there is high agreement among the different victim models. We found that high agreement queries were better suited for model extraction.
This finding parallels prior work on out-of-distribution detection, which found that the confidence score of an ensemble of classifiers is much more effective in finding out-of-distribution inputs compared to a single over-confident classifier. We can hypothesize that consensus among models that make up the ensemble was indicative of our queries being closer to the real data distribution.
These results suggest that the closeness of the queries to the original training data’s input distribution is an important factor in determining the effectiveness of distillation or model extraction. Note that this query selection strategy is not a practical attack since (1) a large pool of queries and victim model outputs need to be collected in order to begin filtering queries, and (2) the predictions of an ensemble of victim models might not be readily available to the attacker.
Is it possible to defend APIs against model extraction?
Current defenses only work against naive adversaries. We investigated two strategies to defend machine learning APIs against model extraction:
- detecting queries that could be part of a model extraction attack.
- watermarking predictions made by the API to later claim ownership of models that were extracted.
While both defenses were effective to some degree, they work only in limited settings — sophisticated adversaries might anticipate these defenses and develop simple modifications to their attacks to circumvent these defenses.
Defense against model extraction is a tricky open problem. An ideal defense should preserve API utility. It should also be hard for adversaries aware of the defense to circumvent it.
Conclusion
In this work, we studied model extraction attacks in natural language processing. We efficiently extracted both text classifiers and question answering (QA) models. These attacks are quite simple and should be treated as lower bounds to more sophisticated attacks leveraging active learning. We hope that this work highlights the need for more research in the development of effective countermeasures to defend against model extraction, or at least to increase the cost of adversaries. Defenses should strive to have a minimal impact on legitimate users of the model. Besides work on attack-defense mechanisms, we see two other avenues for future research:
1) Improving Distillation - Since distillation is possible with random sequences of tokens, our approach might be a good way to perform distillation in low-resource NLP settings where the original training data cannot be made available. Random sequences (perhaps with the intelligent data selection strategy) could also be used to augment real training data for distillation.
2) Closeness of Input Distributions - Model extraction might be a good way to understand the closeness between two input distributions, where one input distribution is used to extract a model trained on another input distribution. This technique could be used as a method to tackle an important open problem in NLP (“What is a domain?”).
Where to find the paper and code?
This blog post summarizes the results in our ICLR 2020 paper “Thieves on Sesame Street! Model Extraction of BERT-based APIs”. You can find the camera ready version of the paper here and the code to reproduce experiments here.
How to get in touch with the authors?
This work was done by Kalpesh Krishna (during an internship at Google AI Language), Gaurav Singh Tomar, Ankur P. Parikh, Nicolas Papernot and Mohit Iyyer. We are happy to get in touch and hear any feedback / answer any questions at kalpesh@cs.umass.edu!
Acknowledgements
We thank the anonymous reviewers, Julian Michael, Matthew Jagielski, Slav Petrov, Yoon Kim and Nitish Gupta for helpful feedback on the project. We are grateful to members of the UMass NLP group for providing the annotations in the human evaluation experiments. Finally, we thank Mohit Iyyer, Arka Sadhu, Bhanu Teja Gullapalli, Andrew Drozdov, Adelin Travers, and Varun Chandrasekaran for useful feedback on the blog post.