Beyond federation: collaborating in ML with confidentiality and privacy
by Adam Dziedzic, Christopher A. Choquette-Choo, Natalie Dullerud and Nicolas Papernot
Collaboration is a key component of learning, for both humans and machine learning. Doctors commonly ask their colleagues for diagnosis recommendations to improve their own, like referring patients to specialists.
In machine learning, it is frequent to obtain better predictions by collaboratively polling the predictions of multiple machine learning models (a technique often known as ensemble learning). For instance, collaboration can help improve a model’s performance by increasing the amount and breadth of training data available. Collaboration can be especially helpful on specialized cases that were never before observed by a model owner, such as rare genetic diseases. In the healthcare setting, certain hospitals often specialize in treating particular diseases. Therefore, hospitals may have an abundance of data for particular maladies, and very little for others. Consider two hospitals specializing in cardiac treatment and respiratory treatment, respectively. Given that both train a machine learning model on their own data, the former’s model may struggle on non-cardiac data and the latter on non-respiratory. Thus, these two hospitals may want to collaborate so that they can cover each other’s weaknesses.
A simple method for our imagined hospitals is pooling their data into one large training set. A model trained on the union of their data will be able to reliably provide diagnoses for more diseases. However, many applications of machine learning (e.g., healthcare and banking) cannot use this technique because of the sensitive nature of the training data.
Another intuitive approach, which we build off in our work, is to enable collaboration by using each other’s models to label new data. If our cardiac hospital gets a patient with an evident respiratory problem, they can instead send the patient data to the respiratory hospital and use their machine learning model to provide a reliable prediction. Including this newly labeled datapoint in their dataset can help improve their machine learning model on respiratory disease diagnoses.
This approach, however, requires that all of the models that form the ensemble have access to the input which they need to predict on. It also requires that all the model owners (participating in the ensemble) be comfortable with revealing the prediction of their model, which can leak private information about the underlying data. In the case of collaborating doctors, and many other application domains involving sensitive data like healthcare or banking, the privacy of user data is pertinent. These privacy requirements, often imposed through regulations, are beneficial to us as individuals but create extra challenges for collaboration in machine learning
The CaPC protocol
In our work, called CaPC, which stands for Confidential and Private Collaborative Learning, we provide a protocol for enabling machine learning models to collaborate while preserving the privacy of the underlying data. This enables us to have an ensemble of distributed models collaboratively predict on an input without ever having to reveal this input, the models themselves, or the data that they were trained on. We reason about privacy through two lenses:
- Confidentiality of the data and models is maintained if data is never accessed in its raw form, i.e., the data is encrypted using some cryptographic method rather than transmitted in plaintext. This prevents models in the ensemble from reading the input they are predicting on (we will see later how they can still predict on the input thanks to cryptography). It also means we don’t have to centralize all of the models in a single location, so these models’ confidentiality (parameter values, architectures, etc.) is also preserved.
- Privacy of the data is often reasoned about using the differential privacy framework, which protects the privacy of individuals by guaranteeing that their training record won’t overly influence the outcome of the analysis. For example, a doctor learning that large tumours are indicative of cancer should learn that conclusion regardless of if a single patient’s cancer data was included.
In other words, confidentiality protects what can be learned from seeing data (e.g., as an input to a system) whereas privacy protects what can be learned from statistics about the data (e.g., from the output of systems trained on the data). To come back to our running example, our secure approach protects both the confidentiality of the data being shared between hospitals (i.e., the respiratory hospital should not see the data that it was asked to label in plaintext because the data is encrypted) and limit any (differential) privacy leakage from the respiratory hospital’s model (i.e., limit what the cardiac hospital can learn about the respiratory hospital’s patients using the obtained predictions). This is exactly what CaPC provides.
Here is a talk about our work which complements the rest of this blog post.
How does CaPC work?
CaPC integrates building blocks from cryptography and differential privacy to provide Confidential and Private Collaborative learning. Extending our example above, Figure 1 formalizes the collaborative learning setup. The querying party is any party (e.g., the cardiac hospital) with unlabeled data. They send their data to a number of answering parties (the ensemble), who each label this data point with their own machine learning models. The protocol finalizes with the aggregate label returned to the querying party.
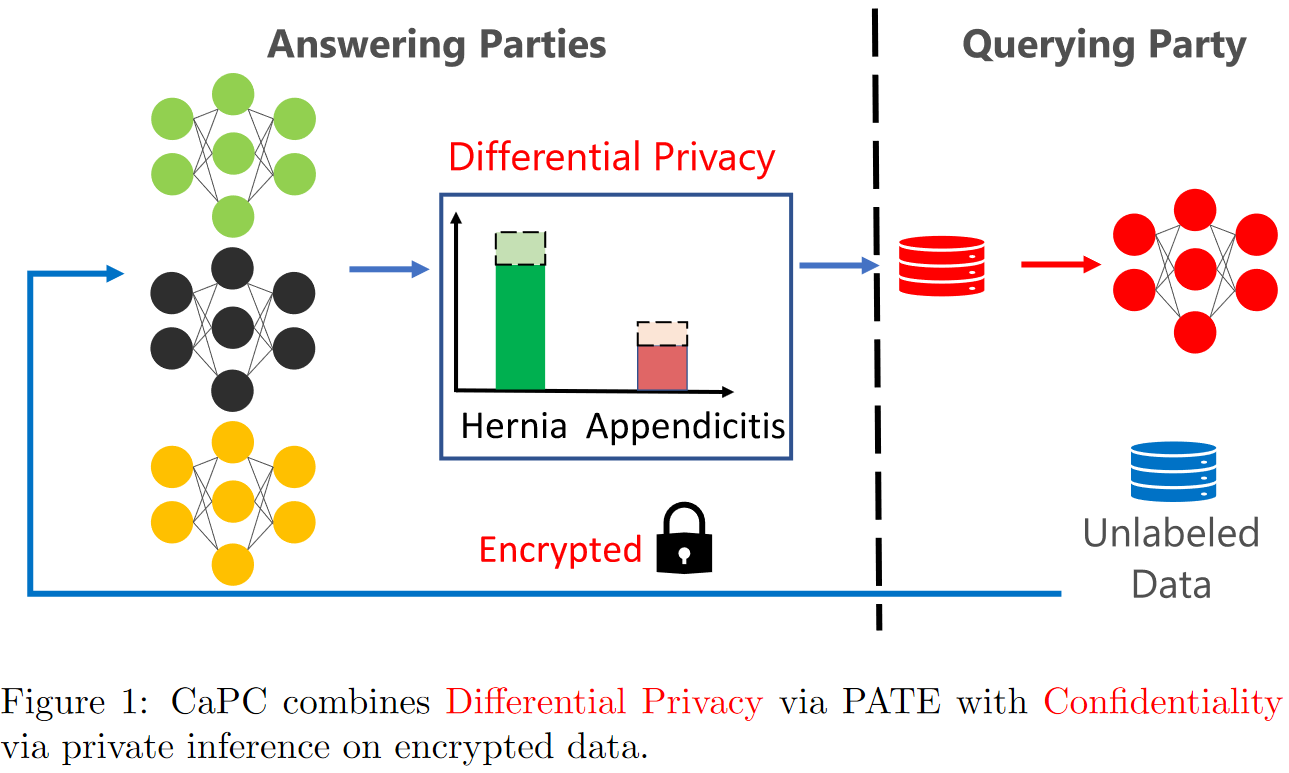
To protect confidentiality, the querying party will encrypt their data using Homomorphic Encryption prior to sending it to any answering party. Homomorphic encryption is a special type of encryption that enables linear arithmetic on the data, e.g., encrypting a data point, then adding 5, and unencrypting will yield the original data plus 5 (the same property holds for multiplication). As we will see, this is an important property that CaPC relies on that most forms of encryption do not provide. It allows the answering parties to predict on the encrypted input without decrypting it first.
To protect privacy (in the sense of differential privacy), we do not reveal the individual predictions of each model. Instead, we use a voting mechanism to return a single aggregate prediction. Each answering party will vote on a label for the input data point, resulting in a histogram of votes, and the class with the most votes will be the returned label. However, this naive voting mechanism can still leak information about the training data which each answering party used to learn their own model. For instance, if votes are equally split between two classes, then one party changing their vote will swap the returned aggregate label. This change in prediction could happen for instance if this party had suddenly overfitted to a new specific training point. To prevent and protect privacy in a differential privacy sense, we need to add some (random) noise to the histogram before we return the highest voted label. There are many ways to add noise and construct a differentially private voting scheme, in our case, we use PATE, which provides a state-of-the-art privacy-utility trade-off for our scenario. Readers familiar with the PATE framework will note that in CaPC, any party can play the role of either a student (querying party) or teacher (answering party), depending on which party initiates the protocol as the querying party.
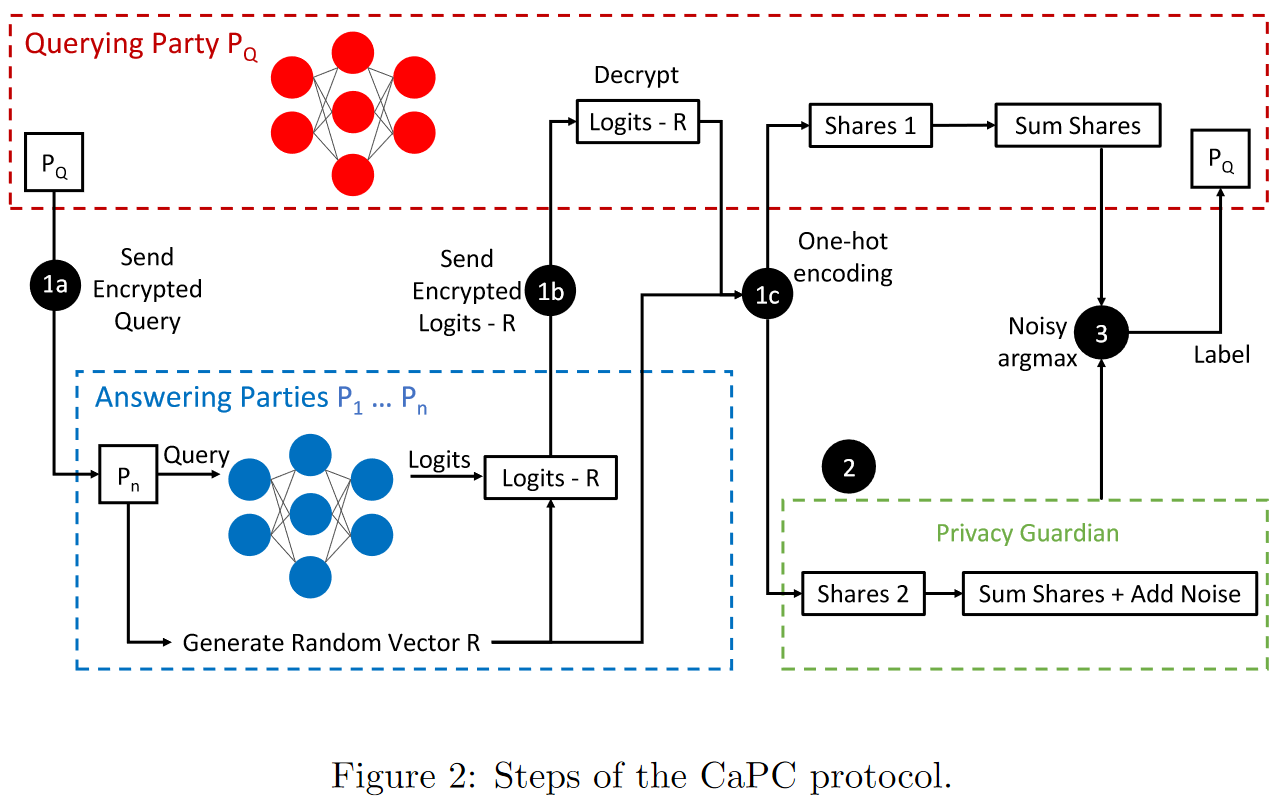
Figure 2 summarizes these steps, which we now describe in more detail. Readers not interested in the low-level technical details of CaPC can skip to the next section titled Why use CaPC?.
First, any party will initiate the protocol as the querying party. In step 1a, the querying party will send their homomorphic encrypted data to all answering parties. Then, all the answering parties will use private inference to get the model logits (the unnormalized model predictions for each class) on the encrypted data. In Step 1b, to prevent differential privacy leakage, each answering party will secret share their logits with the querying party by subtracting a random vector R from them before sending. This acts as a form of encryption preventing the querying party from gaining plaintext access to the logits before PATE. In Step 1c, the querying party and each answering party engage in a 2PC protocol which computes the one-hot encoding of the logits (a binary vector with 1 only at the index of the predicted class). The querying party and answering party each receive one share of the one-hot encoding, such that summing the two shares reveals the true one-hot encoding; this prevents either party viewing the vector in plaintext.
In Step 2, each answering party sends its share to a Privacy Guardian (PG) who sums the shares and adds noise to achieve the differential privacy guarantee of PATE. At the same time, the querying party sums its shares. Finally, in step 3, the Privacy Guardian and querying party engage in 2PC to sum each of their summed shares, which removes the secret sharing to reveal the plaintext (noisy) value. The result is the differentially private final label.
Why use CaPC?
CaPC:
- Provides complete data protection through confidentiality and privacy.
- Provides a realistic and practical setup for collaboration (see Improving Practical Collaboration below).
- Greatly improves performance on rare and/or low-performing classes by using active learning.
CaPC or Federated Learning?
Vanilla federated learning (FL) is a collaborative learning method that provides confidentiality but not privacy. Even if data is not shared directly because participants only share gradients, sensitive information can still be leaked because these gradients still contain it. Because federated learning does not provide differential privacy guarantees, the privacy of sensitive user data could be breached and potentially recovered by participants of the federated learning protocol or the central party.
An example of such an attack was introduced in recent work by [1]. They show that given white-box (full) access to a model, they can breach privacy by performing membership inference: determining if a data point was used to train a model. Their method achieves a high attack accuracy by observing the gradients of data points and inferring members as those that have low values (in some Lp-norm).
Further, if the central server is curious, tracking the model updates from each party could reveal information about their individual training datasets. As well, a single participant can learn information about the union of the other training datasets by observing how specially crafted model updates interact with the new global model at each SGD iteration—leaking information about their private data.
These attacks reveal that federated learning makes unrealistic assumptions about the trust placed by participants in the central party. Other extensions to FL to include differential privacy require billions of users to achieve reasonable guarantees. These requirements limit its practical usage to few industry players.
Meanwhile, the above attacks and more do not work in CaPC. The centralized Privacy Guardian only receives (secure) shares of outputs from each answering party, and has no access to model parameter updates in training. Therefore, a curious Privacy Guardian does not pose a threat while curious central servers do.
Similarly, neither an answering party nor querying party can gain information about each other’s training data: the querying party’s data is protected by encryption, and the answering party’s data is guaranteed differential privacy through the noise added by the PATE mechanism.
Improving Practical Collaboration
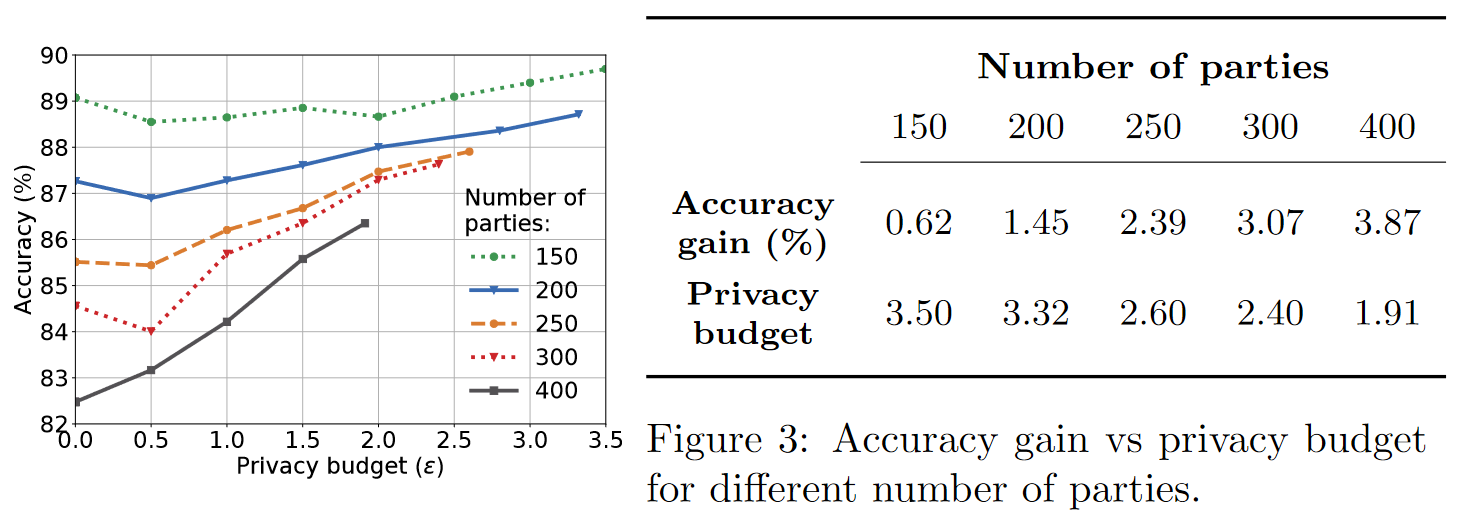
Low Number of Participants Prior work, including FL, require many thousands (vanilla) or millions (differentially private FL) of participants to engage in training to learn performant models. On the other hand, Figure 3 shows that CaPC observes accuracy gains of nearly 4 percentage points on only 400 models with a tight privacy budget of less than 2. CaPC is effective with many orders of magnitude fewer participating parties than FL. The range of required parties (10s or 100s) for CaPC is also much more realistic in practice. When more parties participate, the privacy-utility tradeoff of CaPC improves greatly.
Distinct Model Architectures Much prior work assumes a single model architecture across all parties. This includes federated learning where all participants must share exactly the same model. This restriction may force participating parties to undergo expensive retraining to collaborate, and also limits any additional benefits of having fine-tuned architectures for each party’s specific dataset. Instead, CaPC enables each querying party to train their own distinct architectures, providing a more flexible collaboration protocol. For instance, a party could use an AdaBoost classifier while the other party uses a neural network model based on the ResNet architecture. In these heterogeneous settings, we see that CAPC can boost a querying party’s accuracy by roughly 2.6 percentage points.
Improving Fairness CaPC also enables improvements in underrepresented data groups. When we force the training distributions of each party to contain mainly data points from one class, we see that their performance undesireably drops on other classes. By engaging in CaPC, the performance on these underrepresented classes improves greatly, as shown by an increase in balanced accuracy of 5.7 percentage points.
Improving CaPC
CaPC can provide many benefits to collaboration; however, there are still many improvements that can be made to CaPC. In particular, performing private inference with each answering party is by far the slowest component of the protocol. Improving the efficiency of these methods will directly improve CaPC’s computational efficiency. Though data privacy is protected, the particular cryptographic primitive we use (two party computation) to compute nonlinearities can leak model architecture decisions. CaPC affords much greater flexibility than previous approaches like federated learning in terms of the number of participants, model architecture heterogeneity, and security assumptions made by the protocol participants. But, there is still room to grow. We believe that with more work CaPC could provide benefits to as few as a handful of participants and protect against colluding parties or a dishonest Privacy Guardian.
Want to read more?
You can find more information in our main paper. Code for reproducing all our experiments is available in our GitHub repository.
Acknowledgments
We would like to thank our co-authors for the many inputs on the present blog post and for their contributions to the work presented here: Yunxiang Zhang, Somesh Jha, and Xiao Wang.
[1] Milad Nasr , Reza Shokri , Amir Houmansadr: Comprehensive privacy analysis of deep learning: Passive and active white-box inference attacks against centralized and federated learning. 2019 IEEE Symposium on Security and Privacy (SP), May 2019.